K3s & Rancher Setup Guide
Ein praktischer Schritt-für-Schritt-Guide zur Einrichtung eines produktionsnahen K3s-Clusters mit Rancher – inklusive Sicherheitsfeatures und Automatisierung mit Terraform.

Wie man Rancher Server und K3s auf Bare Metal installiert
Der Rancher Server ist ein Kubernetes-Orchestrierungsmodul, mit dem sich Cluster komfortabel verwalten lassen – ganz gleich, ob sie in der Cloud oder On-Premises betrieben werden.
Zielgruppe
Dieser Artikel richtet sich an fortgeschrittene Entwickler, DevOps-Engineers und Admins, die einen Kubernetes-Cluster mit Rancher auf eigener Hardware (Bare Metal) installieren möchten. Das Setup ist speziell für Test- und Entwicklungsumgebungen gedacht, legt aber bereits Wert auf Produktionsnähe, etwa durch:
- TLS-Absicherung
- Secrets-Verschlüsselung
- Wiederholbare Bereitstellung mit Terraform
Grundkenntnisse in Kubernetes, Helm und Terraform werden vorausgesetzt.
Warum Helm & Terraform?
Für die Installation von Rancher setzen wir auf zwei bewährte Tools:
-
Helm ist der Standard, um Kubernetes-Anwendungen einfach, reproduzierbar und flexibel bereitzustellen. Rancher wird offiziell als Helm-Chart ausgeliefert, wodurch Updates und Konfiguration erheblich erleichtert werden.
-
Terraform nutzen wir, um die komplette Bereitstellung (Namespace, Secrets, Helm-Installation) deklarativ und wiederholbar zu automatisieren. Damit kann der gesamte Prozess später problemlos in CI/CD-Pipelines integriert oder für verschiedene Umgebungen reproduziert werden.
Diese Kombination ermöglicht ein sauberes, skriptgesteuertes Setup, das sich leicht erweitern und warten lässt.
Rancher Server vs. Rancher Desktop
Rancher gibt es in zwei Varianten. Die Desktop-Variante ist für den lokalen Rechner gedacht und erinnert stark an
Docker Desktop. Man erhält einen Mini-Kubernetes-Cluster, ein Build-Tool (nerdctl) und einfachen Zugriff auf den
Cluster dank eines schnellen Installers. Für Prototyping ist das ideal – wenn jedoch ernsthafte Software entwickelt
werden soll, braucht es leistungsfähigere Werkzeuge. Dafür ist der Rancher Server gedacht.
Was man braucht
Um mit Rancher einen Kubernetes-Cluster zu verwalten, benötigt man zunächst einen bestehenden Cluster, auf dem Rancher installiert werden kann. Wie dieser Cluster bereitgestellt wird, spielt für Rancher keine große Rolle. Da jedoch nicht alle ein komplettes Rechenzentrum zu Hause haben, bieten sich Distributionen wie K3s an, um ein produktionsnahes Kubernetes auf einem einzelnen Node zu betreiben.
Disclaimer: Produktionsnah bedeutet nicht automatisch produktionsreif. Ein produktiver Cluster sollte idealerweise über mehrere physische Maschinen verfügen. Da wir das Ganze hier aber in einem Home-Setup umsetzen, ist die K3s-Distribution bestens geeignet. Weitere Informationen sowie die minimalen Hardware-Anforderungen gibt es hier: K3s Requirements
Als Betriebssystem setzen wir auf Ubuntu, den bewährten Klassiker – konkret nutzen wir Ubuntu Server 24.04.
K3s Installation
Bevor K3s mit einem simplen One-Liner installiert wird:
1
curl -sfL https://get.k3s.io | sh -
sollte man sich vorab einige Punkte anschauen. Gerade beim Thema Cluster- und Container-Orchestrierung gibt es Aspekte, die je nach Umgebung angepasst werden müssen.
Firewall
Vor der eigentlichen Installation muss die Firewall konfiguriert werden, da der Node sonst nicht zuverlässig erreichbar ist. Unter Ubuntu Server wird hierfür der UFW (Uncomplicated Firewall) Befehl verwendet.
Disclaimer:
In diesem Setup kommt ein VPN-Netz mit dem Adressbereich
172.30.0.0/24zum Einsatz. Das bedeutet, der Cluster ist ausschließlich innerhalb dieser Range und über VPN erreichbar. Wird kein VPN genutzt, kann stattdessen das lokale Netzwerk verwendet werden; dieses könnte beispielsweise192.168.178.0/24lauten. Die genaue Adresse lässt sich z. B. über den Befehlip aermitteln.
Aus der Doku von K3s können wir folgende Tabelle als Referenz nehmen:
| Number | Protokoll | Port | Quelle | Ziel | Beschreibung |
|---|---|---|---|---|---|
| 1 | TCP | 2379-2380 | Servers | Servers | Required only for HA with embedded etcd |
| 2 | TCP | 6443 | Agents | Servers | K3s supervisor and Kubernetes API Server |
| 3 | UDP | 8472 | All nodes | All nodes | Required only for Flannel VXLAN |
| 4 | TCP | 10250 | All nodes | All nodes | Kubelet metrics |
| 5 | UDP | 51820 | All nodes | All nodes | Required only for Flannel Wireguard with IPv4 |
| 6 | UDP | 51821 | All nodes | All nodes | Required only for Flannel Wireguard with IPv6 |
| 7 | TCP | 5001 | All nodes | All nodes | Required only for embedded distributed registry (Spegel) |
| 8 | TCP | 6443 | All nodes | All nodes | Required only for embedded distributed registry (Spegel) |
Jetzt muss eine konkrete Auswahl getroffen werden. Gehen wir die Optionen einmal durch:
-
Embedded etcd.
etcd ist eine eingebettete Datenbank für Kubernetes, in der Informationen zum Cluster gespeichert werden. Diese Datenbank wird vollständig von Kubernetes verwaltet und läuft ausschließlich auf den Master-Nodes. HA (High Availability) with embedded etcd bedeutet in diesem Fall, dass – wenn mehrere Master-Nodes vorhanden sind – die etcd-Datenbank über alle diese Nodes hinweg synchronisiert wird. Dies geschieht über die Ports 2379 und 2380. Damit das funktioniert, müssen diese Ports freigegeben werden.Entscheidung: Da es sich hier um einen Single-Node-Cluster handelt, läuft die Datenbank ohnehin nur auf einem Node, sodass die Ports nicht extra freigegeben werden müssen. Werden später jedoch weitere Master-Nodes hinzugefügt, muss die entsprechende Firewall-Regel ergänzt werden.
-
Kubernetes API.
Kurz gesagt: Ja, dieser Port wird benötigt, wenn beispielsweise mitkubectlvon anderen Maschinen aus auf den Cluster zugegriffen werden soll. -
Flannel Backend.
Hier steht die Entscheidung an, welches Backend die CNI-Implementation Flannel nutzen soll. VXLAN ist standardmäßig aktiviert und völlig ausreichend für den vorgesehenen Zweck. Alternativ kann der Netzwerk-Traffic zwischen den Pods nativ mit WireGuard verschlüsselt (–flannel-backend=wireguard-native) oder mit Host-GW (–flannel-backend=host-gw) ganz ohne Overlay betrieben werden.Entscheidung: Da der Node ohnehin nur innerhalb eines VPN erreichbar ist, muss der Traffic zwischen den Pods nicht zusätzlich verschlüsselt werden. Daher bleibt es bei VXLAN, und es muss der Port 8472 freigegeben werden.
-
Kubelet Metrics.
Kubernetes stellt über den Port 10250 diverse Metriken bereit. Damit diese abgerufen werden können und auch andere Nodes darauf zugreifen können, ist es wichtig, diesen Port freizugeben. Allerdings sollte der Port nicht öffentlich erreichbar sein, da er sensible Informationen über den Cluster enthält. In diesem Testsetup wird ein VPN-Netz verwendet, daher wird der Zugriff für alle Adressen innerhalb des VPN erlaubt. Falls kein VPN genutzt wird, muss entweder das LAN-Subnetz oder gezielt die IP-Adressen einzelner Nodes freigegeben werden.
Die restlichen Punkte sind für dieses Setup irrelevant. Weder das Flannel-Backend WireGuard noch der Registry-Cache ( Spegel) werden genutzt.
Die nächste Entscheidung betrifft den Adressbereich, den der Cluster für Pods bzw. Services verwendet. Standardmäßig
nutzt K3s folgende Ranges: 10.42.0.0/16 für Pods und 10.43.0.0/16 für Services. Ohne zu tief in die CIDR-Notation
einzutauchen: /16 bedeutet vereinfacht, dass die ersten beiden Blöcke fix sind. Jede Adresse muss also mit 10.42
bzw. 10.43 beginnen und kann bis 10.42.255.255 bzw. 10.43.255.255 reichen. Das ergibt pro Range rund 65 000
nutzbare IP-Adressen, was in der Regel völlig ausreicht.
Damit die Kommunikation für die Pods und Services nicht durch die Firewall blockiert wird, müssen diese Adressbereiche ebenfalls freigegeben werden.
Final sieht die Firewall-Konfiguration dann so aus:
| Zweck | UFW-Befehl |
|---|---|
| API-Server | sudo ufw allow from 172.30.0.0/24 to any port 6443 proto tcp |
| Flannel VXLAN | sudo ufw allow from 172.30.0.0/24 to any port 8472 proto udp |
| Kubelet Metrics | sudo ufw allow from 172.30.0.0/24 to any port 10250 proto tcp |
| Pods (Cluster-CIDR) | sudo ufw allow from 10.42.0.0/16 |
| Services (Service-CIDR) | sudo ufw allow from 10.43.0.0/16 |
K3s konfigurieren
K3s bietet zahlreiche Konfigurationsmöglichkeiten. Diese alle im Detail zu behandeln, würde jedoch den Rahmen dieses Artikels sprengen. Es gibt jedoch einige sogenannte kritische Konfigurationen, die auf allen Nodes identisch sein müssen, damit der Cluster zuverlässig funktioniert. Diese werden auch explizit in der offiziellen Dokumentation genannt: K3s Config
Es ist außerdem wichtig zu unterscheiden, ob ein K3s Server (Master Node) oder ein K3s Agent (Worker Node) eingerichtet wird. Da hier ein Single-Node-Cluster aufgebaut wird, kommt die Server-Variante zum Einsatz. Zu einem späteren Zeitpunkt könnten problemlos weitere Worker-Nodes oder auch zusätzliche Master-Nodes hinzugefügt werden.
Für dieses Setup wird folgende Konfiguration verwendet:
1
2
3
4
5
6
7
8
9
10
cluster-init: true
secrets-encryption: true
disable-cloud-controller: true
node-name: k3s-master-1
node-ip: 192.168.178.104
advertise-address: 172.30.0.3
tls-san:
- 192.168.178.104
- 172.30.0.3
flannel-iface: wg0
Erklärung der K3s-Konfiguration
Schauen wir uns die einzelnen Konfigurationspunkte kurz an, um zu verstehen, was sie bewirken:
-
cluster-init:
Dieses Flag signalisiert, dass dieser Node den Cluster initialisiert. Nur der erste Node im Cluster (in diesem Fallk3s-master-1) darf dieses Flag gesetzt haben. Weitere Nodes, die später dem Cluster beitreten, lassen es weg. -
secrets-encryption:
Aktiviert die Verschlüsselung der Kubernetes-Secrets in etcd. Das sorgt dafür, dass sensible Daten wie Passwörter oder Tokens verschlüsselt in der Datenbank liegen und erhöht die Sicherheit. -
disable-cloud-controller:
Deaktiviert den Cloud-Controller-Manager, der in Cloud-Umgebungen für das Ressourcen-Management zuständig ist. Da hier ein reines Bare-Metal-Setup (mit VPN) verwendet wird, ist dieser nicht erforderlich. -
node-name:
Bestimmt den Namen des Nodes innerhalb des Clusters. In diesem Fall heißt der Nodek3s-master-1. -
node-ip:
Gibt die IP-Adresse an, unter der der Node lokal erreichbar ist. Hier wurde die lokale Heimnetz-IP192.168.178.104angegeben, damit Services wie der Metrics Server korrekt mit dieser Adresse kommunizieren können. Diese IP muss diejenige sein, über die der Node tatsächlich mit dem Kubelet kommuniziert. -
advertise-address:
Definiert die IP-Adresse, die anderen Nodes (z. B. künftigen Worker-Nodes) im Cluster bekannt gemacht wird. In diesem Fall ist das die VPN-IP172.30.0.3. Sie sorgt dafür, dass die Cluster-Kommunikation (z. B. für den internen Datenverkehr) über das VPN läuft. -
tls-san:
Hier werden zusätzliche IPs angegeben, die in das TLS-Zertifikat aufgenommen werden. Das stellt sicher, dass der Node sowohl über die lokale Heimnetz-IP (192.168.178.104) als auch über die VPN-IP (172.30.0.3) TLS-geschützte Verbindungen akzeptiert. Das ist wichtig, wenn z. B. vom Heimnetz oder VPN auf die API zugegriffen wird. -
flannel-iface:
Gibt explizit das Netzwerk-Interface an, das Flannel für die Pod-Kommunikation nutzen soll. In diesem Fall ist daswg0, also das WireGuard-VPN-Interface. Damit wird sichergestellt, dass der gesamte interne Pod-Netzwerkverkehr über das VPN läuft.
Im Gegensatz zuflannel-backend=wireguard-nativewird hier das bestehende WireGuard-Interface direkt verwendet, um den Datenverkehr zu verschlüsseln. Das Flannel-Backend hingegen würde WireGuard selbst verwalten und intern nutzen. Würden beide Varianten kombiniert, gäbe es am Ende eine doppelte Verschlüsselung – was unnötig wäre. So erhalten wir die Verschlüsselung de facto „gratis“, da WireGuard ohnehin bereits aktiv ist.
Damit sind die wichtigsten Einstellungen sauber erklärt. Natürlich gibt es noch viele weitere Optionen, die je nach Anwendungsfall angepasst werden könnten – aber mit dieser Basis ist das Setup stabil, sicher und für Erweiterungen gut vorbereitet.
Hands-on K3s Installation
Jetzt, wo alle Vorbereitungen abgeschlossen sind, kann der Cluster aufgesetzt werden. Die zuvor erstellte Konfiguration
wird auf dem Server unter folgendem Pfad abgelegt: /etc/rancher/k3s/config.yaml
Das ist der Standardpfad, sodass K3s die Konfiguration automatisch berücksichtigt.
Danach einfach folgenden Befehl in der Konsole ausführen:
1
curl -sfL https://get.k3s.io | sh -
Die Installation läuft dann vollständig durch.
Das finale Ergebnis sollte in etwa so aussehen:
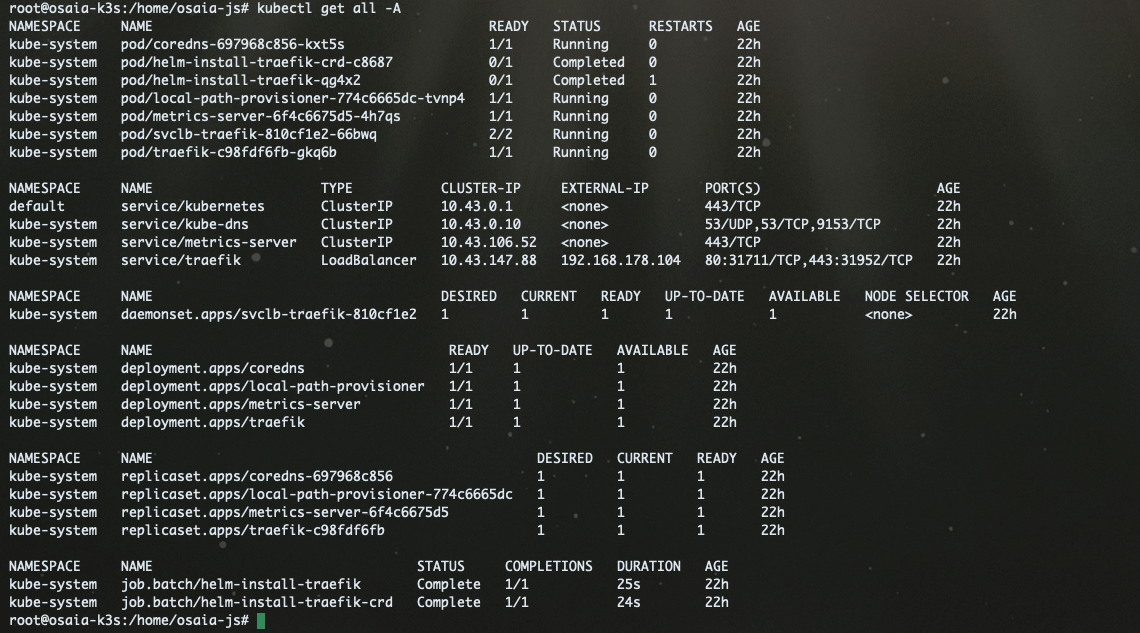
Zugriff über Kubectl
Damit auch von einer anderen Maschine auf den Cluster zugegriffen werden kann, muss das Admin-Zertifikat vom Host kopiert werden.
Disclaimer:
In dieser Demo wird dieser Weg als einfache Zugriffsmöglichkeit verwendet. In einer Produktionsumgebung sollte der Zugriff unbedingt besser abgesichert werden. Ideal ist es, Keycloak einzusetzen, um die User über OIDC zu verwalten, oder Ranchers integriertes User-Management zu nutzen, das einen ähnlichen Zweck erfüllt. Alternativ lässt sich Keycloak mit Rancher koppeln, um alle Benutzer zentral zu verwalten.
Mit folgendem Befehl kann die Konfiguration per SCP vom Server in den Standardpfad für kubectl auf der eigenen
Maschine kopiert werden:
1
scp <USER>@<SERVER>:/etc/rancher/k3s/k3s.yaml ~/.kube/config
⚠️ Achtung: Eine vorhandene lokale Config wird dadurch überschrieben!
Anschließend muss in der Config die Server-IP angepasst werden, da sie standardmäßig auf localhost verweist. Hier muss
die IP des Nodes eingetragen werden. Da diese IP nur im VPN-Netz erreichbar ist, muss das VPN aktiv sein, damit der
Zugriff funktioniert.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: ...
server: https://127.0.0.1:6443 # <-- ersetzen durch die Node-IP
name: default
contexts:
- context:
cluster: default
user: default
name: default
current-context: default
kind: Config
preferences: { }
users:
- name: default
user:
client-certificate-data: ...
client-key-data: ...
Nun können wir von der Maschine aus auf den Cluster innerhalb des VPN zugreifen:
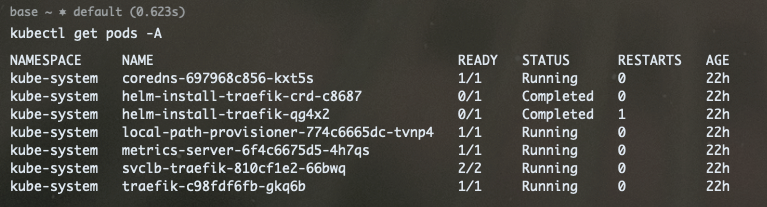
Rancher Server installieren
Jetzt, wo der Cluster läuft, kann der Rancher Server über ein Helm-Chart installiert werden. Auch hier müssen wir genau prüfen, welche Voraussetzungen erfüllt sein müssen und welche Konfigurationen sinnvoll sind.
Die Rancher-Dokumentation ist zwar recht umfangreich, aber an manchen Stellen nicht ganz leicht verständlich. Der
zentrale Einstiegspunkt für unser Vorhaben ist hier zu finden:
Rancher Doc
Im Wesentlichen gibt es zwei zentrale Punkte, die beachtet werden müssen:
- Ingress: Damit die Rancher UI überhaupt erreichbar ist.
- Zertifikatsmanagement: Es muss entschieden werden, wie die TLS-Zertifikate verwaltet werden.
Ein Ingress wird von Rancher automatisch angelegt. Wenn der in K3s eingebaute Ingress-Controller Traefik verwendet
wird, muss hier normalerweise nichts weiter beachtet werden. Wird hingegen der NGINX Ingress Controller eingesetzt,
muss sichergestellt sein, dass dieser auch Ingresses ohne explizit angegebene IngressClass verarbeitet. Traefik
übernimmt das standardmäßig.
Wichtig ist außerdem, dass der Hostname angegeben wird, unter dem Rancher später erreichbar sein soll. Dies kann z. B. mit folgendem Flag gesetzt werden:
1
--set hostname=rancher.my.org
Optionen für Zertifikate
Beim Thema Zertifikate gibt es drei mögliche Ansätze:
-
Self-Signed, von Rancher verwaltet:
Rancher generiert und verwaltet selbstsignierte Zertifikate. Das ist für Test- oder Entwicklungsumgebungen schnell und unkompliziert, jedoch nicht für den produktiven Einsatz geeignet, da Browser diese Zertifikate als unsicher einstufen. -
Let’s Encrypt über cert-manager:
Rancher nutzt den cert-manager, um automatisch Zertifikate von Let’s Encrypt zu beziehen. Diese Option eignet sich ideal für öffentlich erreichbare Rancher-Instanzen, da die Zertifikate von einer vertrauenswürdigen CA stammen und automatisch erneuert werden. -
Eigene Zertifikate ohne cert-manager:
Hier werden eigene Zertifikate (z. B. von einer internen CA) manuell bereitgestellt und von Rancher verwendet. Diese Variante ist sinnvoll, wenn bereits ein internes PKI-System vorhanden ist oder die Zertifikatsverwaltung firmenintern erfolgen soll.
In diesem Setup wird Option 3 verwendet, da ein eigenes Zertifikat zur Verfügung steht. Zertifikate in Kubernetes sind grundsätzlich unkompliziert zu handhaben: Es wird ein Secret im selben Namespace angelegt, das die Zertifikate als Key-Value-Paare speichert. Dieses Secret kann anschließend im Ingress referenziert werden.
Zum Beispiel so:
1
2
3
4
5
6
7
8
9
10
11
12
13
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
namespace: ${namespace}
annotations:
kubernetes.io/ingress.class: "traefik"
traefik.ingress.kubernetes.io/router.entrypoints: "websecure"
spec:
tls:
- hosts:
- ${hostname}
secretName: example-tls
Zusammengefasst müssen folgende Schritte durchgeführt werden:
- Einen Namespace anlegen (es empfiehlt sich, den Standard-Namespace
cattle-systemzu verwenden), - darin ein Secret mit den Zertifikaten erstellen,
- die entsprechende Konfiguration bei Rancher setzen
- und schließlich den Helm-Chart installieren.
Für diesen Ablauf wurde ein Terraform-Skript vorbereitet, das den gesamten Prozess automatisiert.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# main.tf
terraform {
required_providers {
helm = {
source = "hashicorp/helm"
}
kubernetes = {
source = "hashicorp/kubernetes"
version = "2.35.0"
}
}
}
locals {
namespace = "cattle-system"
}
resource "kubernetes_namespace" "rancher_ns" {
metadata {
name = local.namespace
}
}
resource "kubernetes_secret" "cert_tls" {
depends_on = [kubernetes_namespace.rancher_ns]
metadata {
# Name ist von Rancher vorgegeben
name = "tls-rancher-ingress"
namespace = local.namespace
}
type = "kubernetes.io/tls"
data = {
"tls.crt" = var.crt
"tls.key" = var.crt_key
}
}
resource "helm_release" "rancher-server" {
chart = "rancher"
name = "rancher"
repository = "https://releases.rancher.com/server-charts/stable"
namespace = local.namespace
create_namespace = false
set {
name = "hostname"
value = var.hostname
}
set {
name = "bootstrapPassword"
value = var.bootstrapPassword
}
set {
name = "ingress.tls.source"
value = "secret"
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# variables.tf
variable "bootstrapPassword" {
type = string
sensitive = true
nullable = false
description = "Bootstrap-Passwort für den ersten Rancher-Login"
}
variable "hostname" {
type = string
nullable = false
description = "Hostname für den Rancher-Ingress"
}
variable "crt" {
type = string
nullable = false
sensitive = true
}
variable "crt_key" {
type = string
nullable = false
sensitive = true
}
Lokal kann dann eine terraform.tfvars-Datei angelegt werden, um die Variablen zu setzen:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
bootstrapPassword = "RANDOM_STRING"
hostname = "rancher.osaia.cloud"
crt = <<EOF
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
EOF
crt_key = <<EOF
-----BEGIN RSA PRIVATE KEY-----
...
-----END RSA PRIVATE KEY-----
EOF
Wichtig: Das Zertifikat muss zwingend als Fullchain vorliegen. Das bedeutet, dass nicht nur das eigentliche
Zertifikat enthalten sein muss, sondern auch alle Intermediate-Zertifikate der Zertifizierungskette – und das in
korrekter Reihenfolge. Fehlen die Intermediate-Zertifikate, wird Kubernetes das Zertifikat ablehnen, da die
Vertrauenskette nicht vollständig ist. Daher unbedingt sicherstellen, dass alle notwendigen Zertifikate (z. B. dein
Domain-Zertifikat + die Intermediates deiner CA) zu einer vollständigen Kette zusammengefügt werden, bevor sie in crt
eingetragen werden.
Disclaimer: In unserem Fall wurde das Zertifikat bei IONOS bezogen. Dort konnten sowohl das eigentliche Zertifikat als auch die Intermediate-Zertifikate separat heruntergeladen werden. Diese mussten manuell zu einer Fullchain zusammengeführt werden. Konkret bedeutete das:
- Dein Domain-Zertifikat (
my-cert.crt)- Die Intermediate-Zertifikate (z. B.
intermediate1.crt,intermediate2.crt)Die Fullchain-Datei wurde dann so erstellt:
Diese kombinierte
fullchain.crtwurde schließlich in diecrt-Variable eingefügt.
Provider-Konfiguration und Ausführung
Damit Terraform mit dem Kubernetes-Cluster und Helm kommunizieren kann, wird zusätzlich eine provider.tf-Datei
benötigt. Dort wird definiert, wie sich Terraform mit dem Cluster verbindet. Für ein klassisches lokales Setup werden
Standardwerte verwendet:
1
2
3
4
5
6
7
8
9
10
provider "kubernetes" {
config_path = "~/.kube/config"
config_context = "default"
}
provider "helm" {
kubernetes {
config_path = "~/.kube/config"
}
}
Damit nutzt Terraform automatisch die lokale ~/.kube/config sowie den default-Context. Falls ein anderes Cluster
oder ein anderer Context angesprochen werden soll, können diese Werte jederzeit angepasst werden.
Terraform ausführen
Sobald alles vorbereitet ist, kann das Terraform-Skript wie gewohnt ausgeführt werden:
1
2
3
terraform init
terraform plan
terraform apply
Nach erfolgreichem Durchlauf ist Rancher inklusive Zertifikate und Ingress vollständig bereitgestellt. Die Rancher UI ist nun über den angegebenen Host erreichbar:
1
https://rancher.osaia.cloud
Mit dem zuvor vergebenen Bootstrap-Passwort (aus der terraform.tfvars) kann man sich nun einloggen:
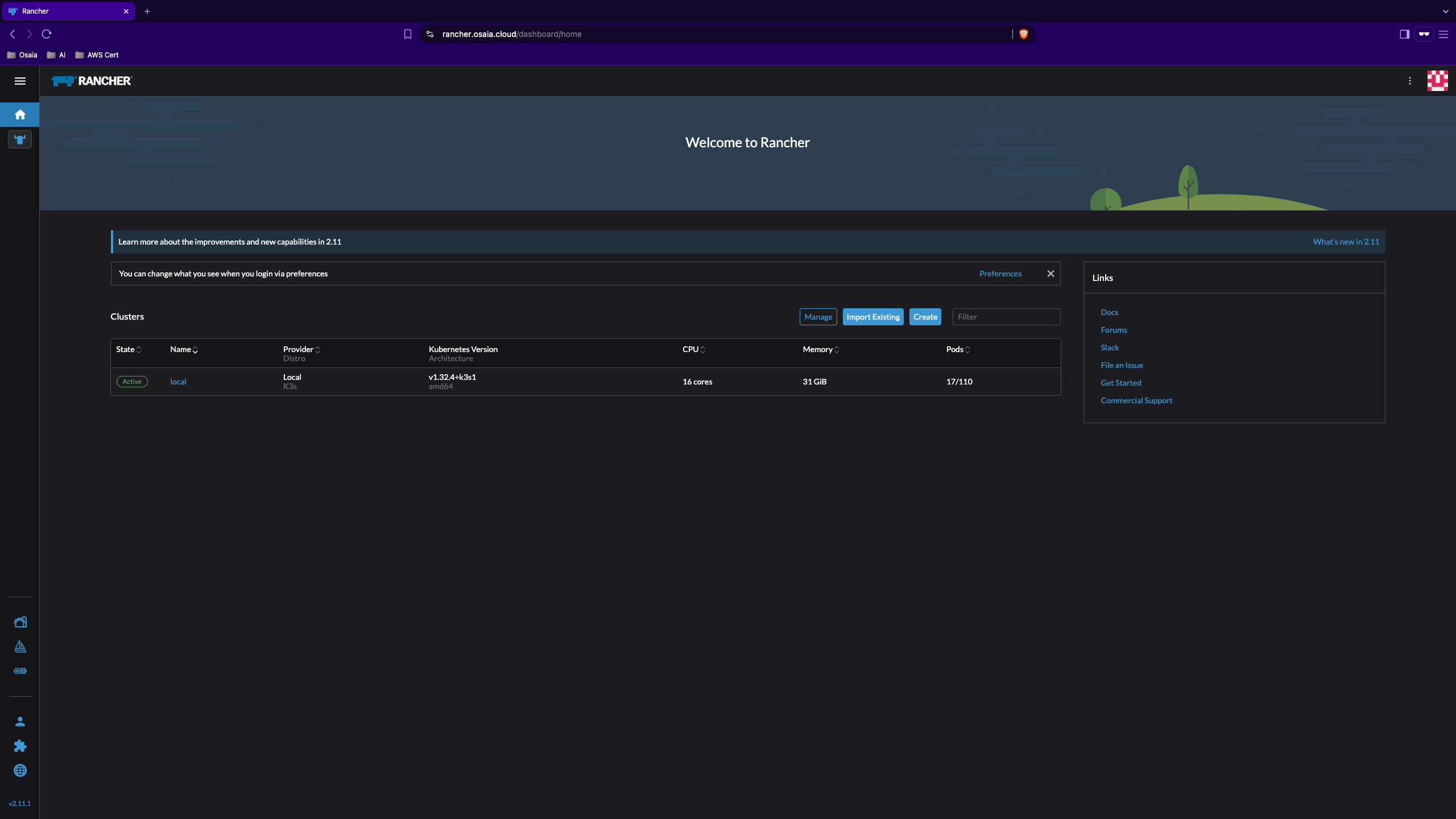
Fazit
Mit diesem Setup steht ein funktionsfähiger, selbst gehosteter Kubernetes-Cluster inklusive Rancher-Management zur
Verfügung.
Die Konfiguration berücksichtigt sinnvolle Sicherheitsaspekte wie VPN-Isolation, TLS-Absicherung und
Secrets-Verschlüsselung – und lässt sich vollständig mit Terraform automatisieren.
Das Setup eignet sich hervorragend für Tests, Entwicklung sowie als technische Grundlage für weiterführende Infrastruktur- oder Automatisierungsprojekte.
👉 Wie geht’s weiter?
In kommenden Artikeln beleuchten wir weitere Themen rund um Kubernetes, darunter alternative Setups mit Juju Charmed
Kubernetes sowie die Integration von Keycloak für Identity- und Access-Management. Damit bauen wir Schritt für
Schritt eine umfassende, produktionsreife Kubernetes-Infrastruktur auf.
Bildnachweis
📸 Image by Mohamed Hassan from Pixabay
Dieser Beitrag wurde erstellt von OSAIA Consulting – Experten für Platform Engineering, Automatisierung und Softwarearchitektur.
💬 Fragen oder Feedback?
Wir freuen uns über den Austausch – schreibt uns jederzeit über unsere Website.